
Craigslist Web Scraper
What is a web scraper?
Web scrapers are programs that extract content from a website. They are used to automate the process of gathering data. In general, they are used by companies to collect data about potential customers or clients. Think product reviews and social media posts. Companies collect data from different social media websites to see what is trending and learn how to better promote their products or services. Web scrapers can also be used to gather product listings. The real estate industry uses web scrapers to collect data about listed properties, gaining a better understanding of the market. Web scrapers can automate the monotonous task of sorting through property listings and aid realtors in striking bargains.
Why I made one
This project was inspired by the desire to save time while browsing Craigslist. The process of clicking in and out of listings and reading descriptions can be time consuming. I wanted to create a program that would get the title, date, and price from all the listings, and from there I could go through my condensed format and find what suited my needs.
Design process
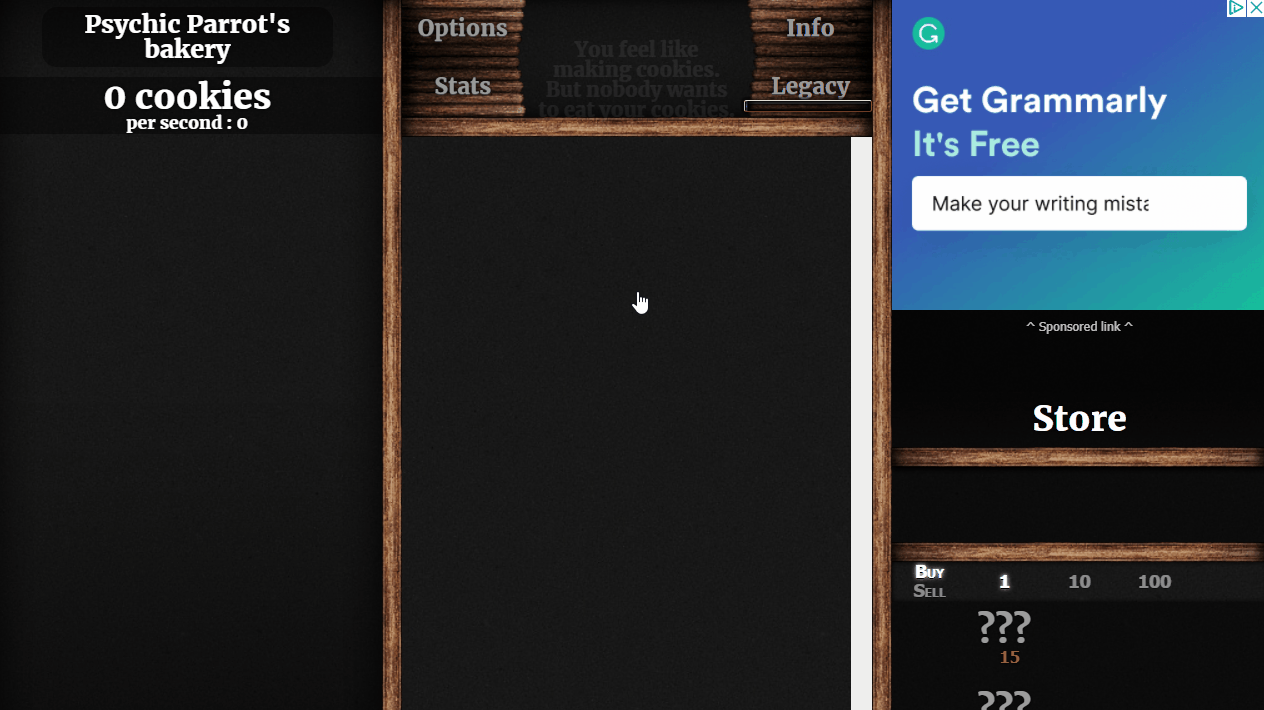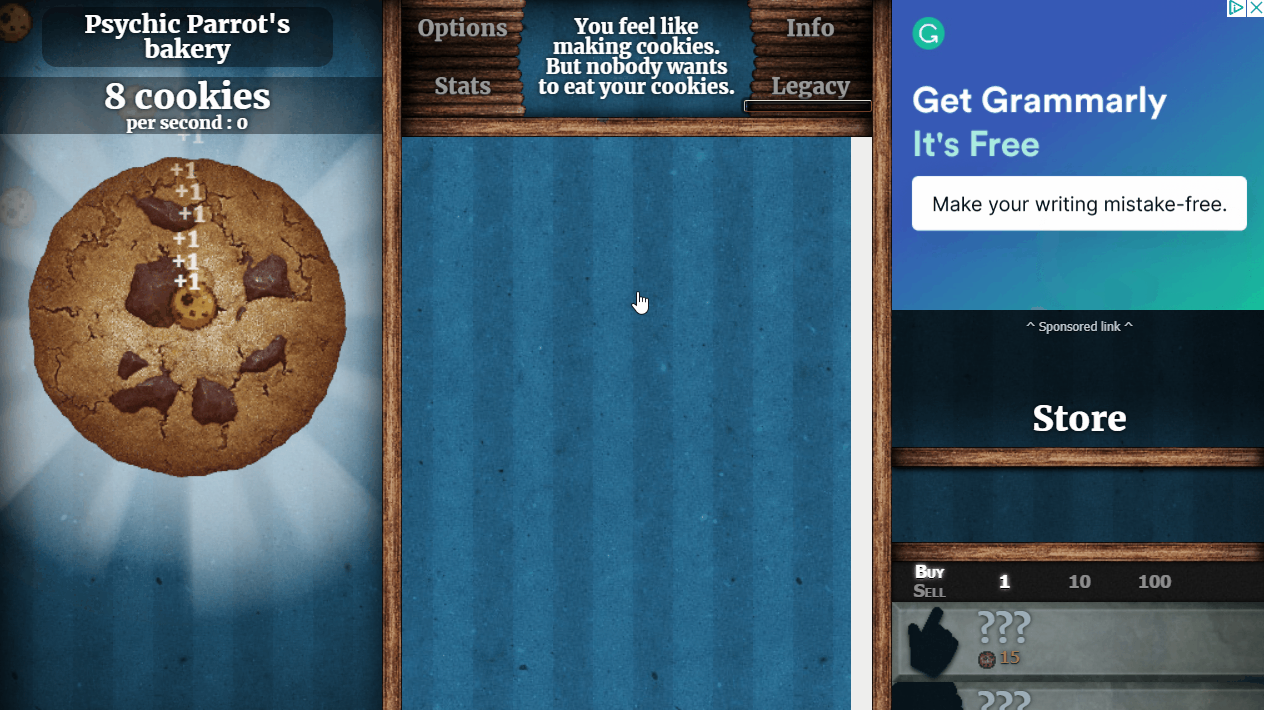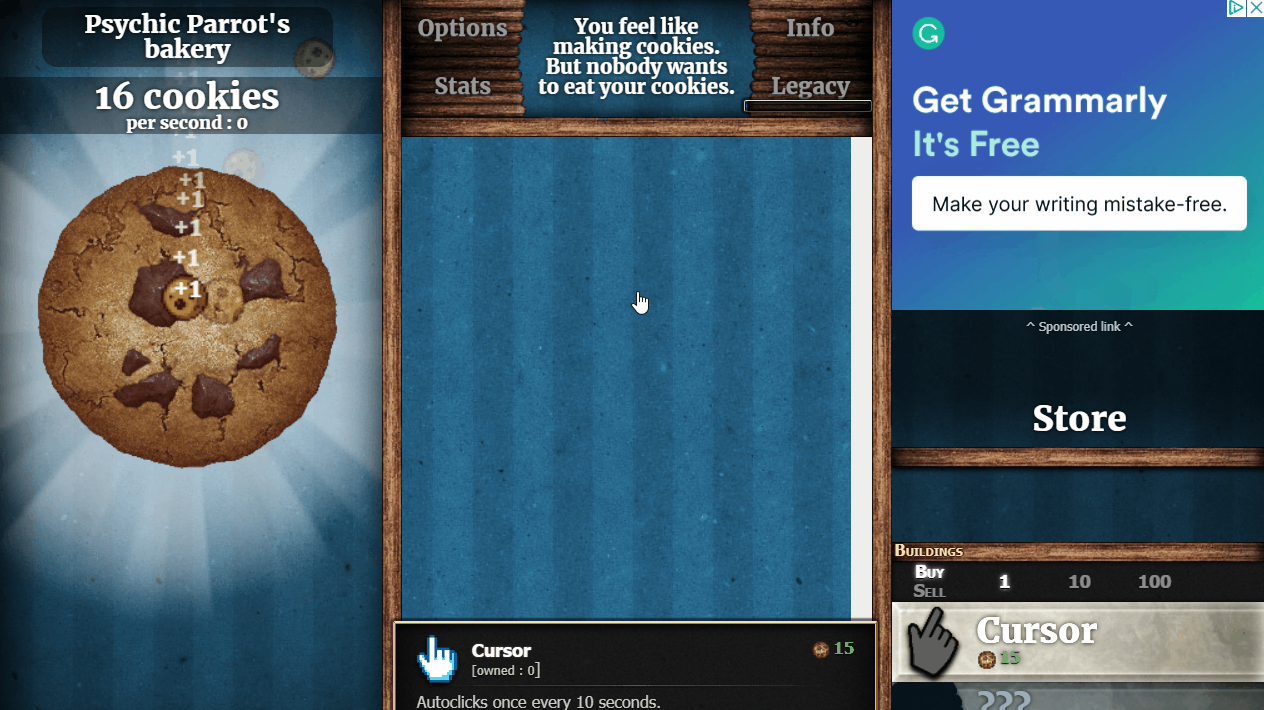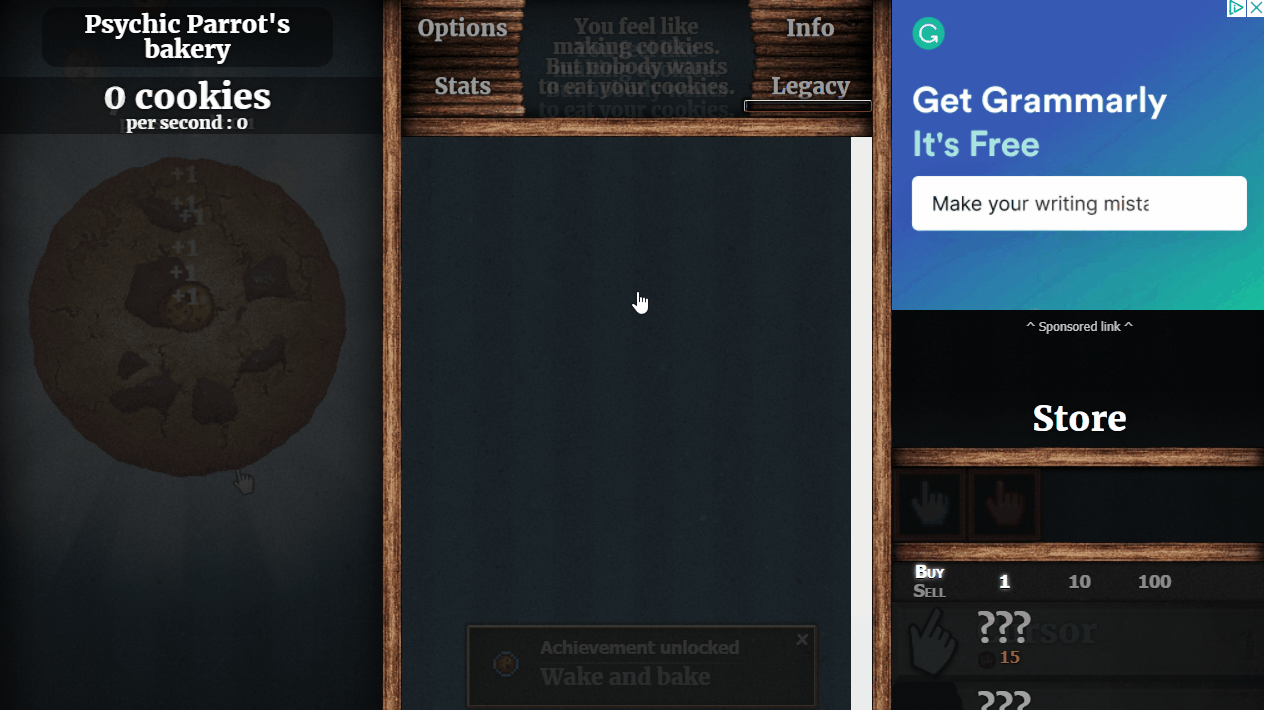
After selecting Selenium’s WebDriver framework, the first thing I needed to do was learn how web scrapers work. I found a tutorial series that taught me the basics of using the Selenium WebDriver libraries in Python. The series covered the topic with some rather interesting examples including a cookie clicker bot. The robot navigates to a cookie clicker website where normally, you would mindlessly click a cookie over and over gaining points, and perform upgrades that accelerate your cookie collecting pursuit. The program scrapes information from the webpage finding the location of the cookie on the screen, the number of cookies collected, and the price and location on the screen of upgrades. It then begins to constantly click the cookie and perform upgrades as they become available. This can be seen below.
My GitHub repository for this project can be seen here.
From this project, I gained the knowledge I needed to create my own web scraper in Python. The bot would navigate to my local Craigslist page and enter a hard-coded search. It then went through the posts and scraped useful information like the date, price, title, and link. After going through all the posts on the page, it printed the condensed information to the console.
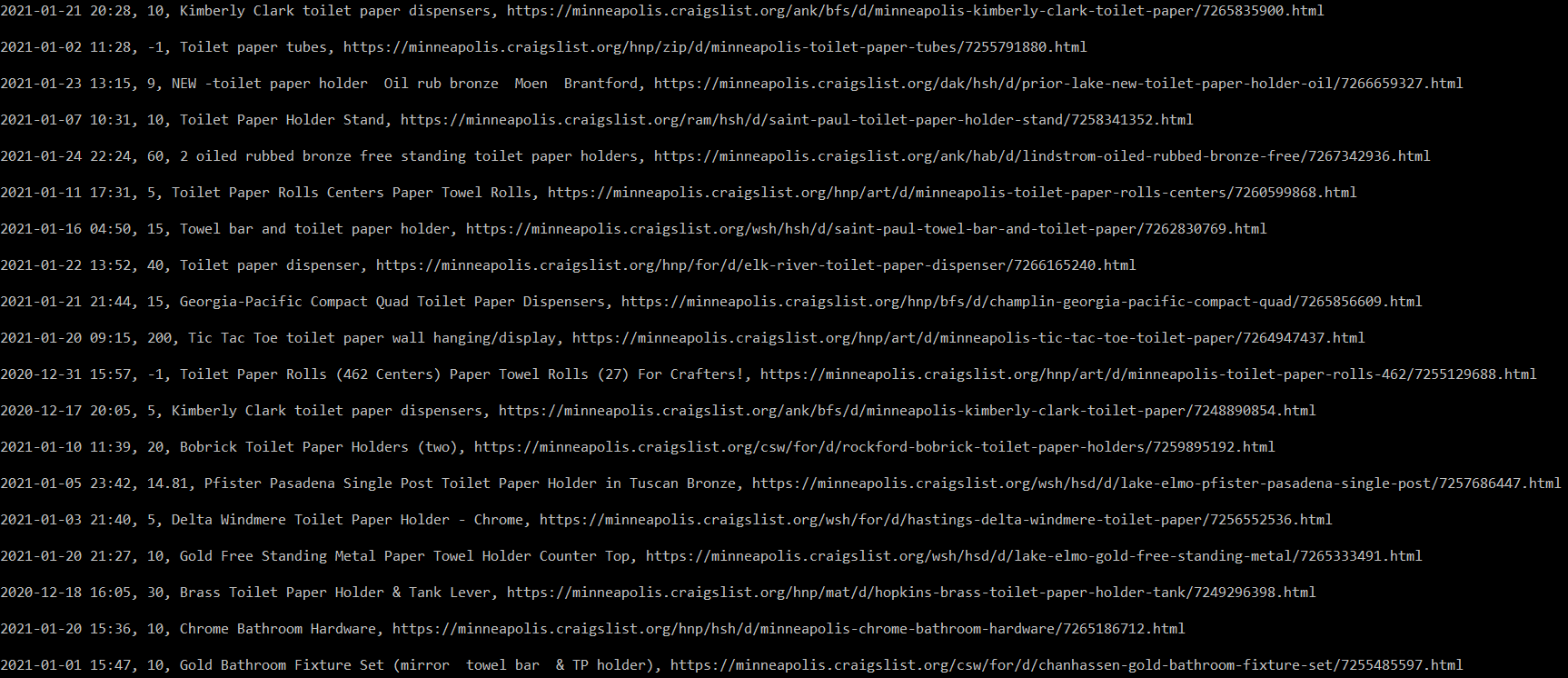
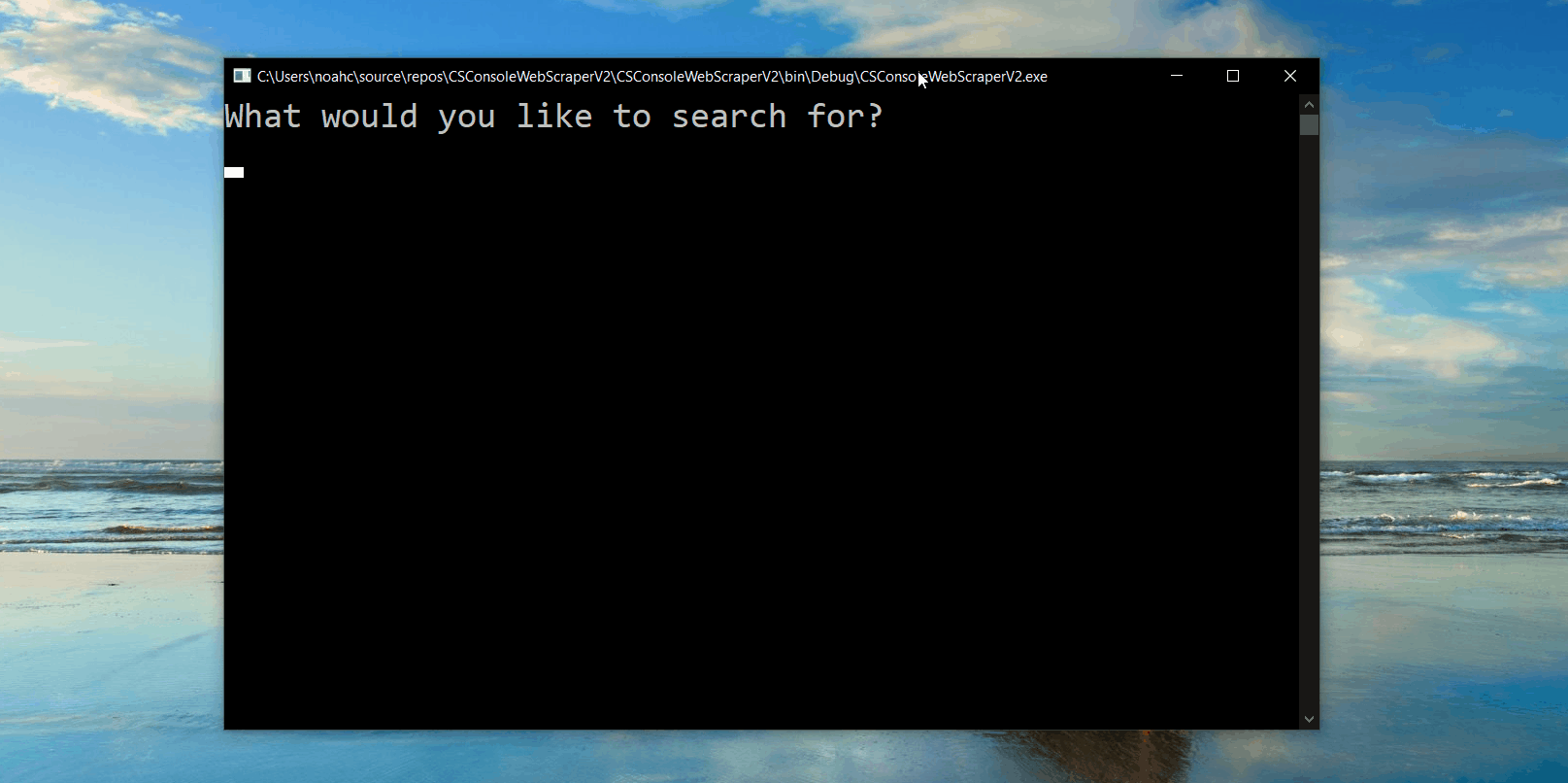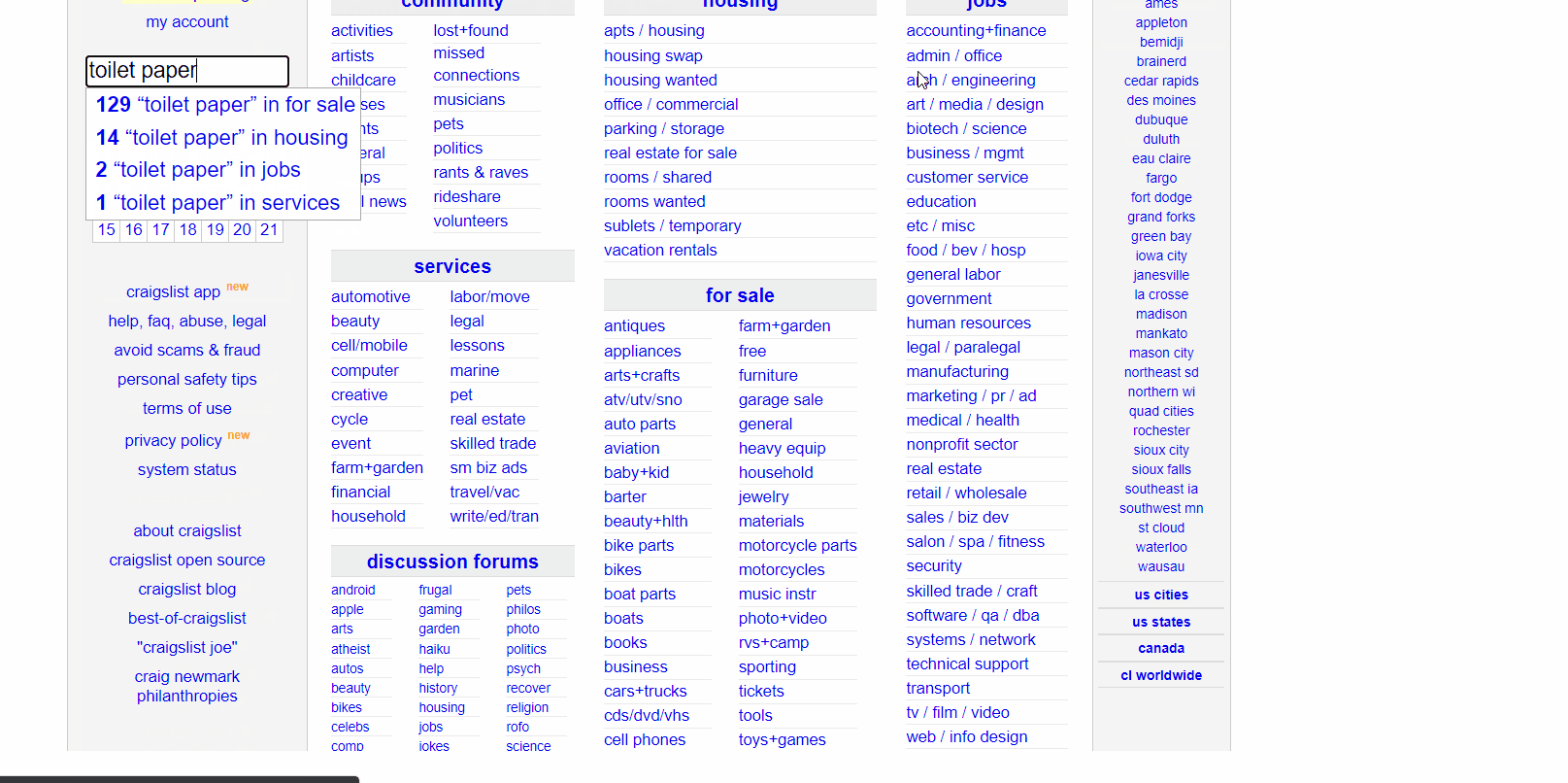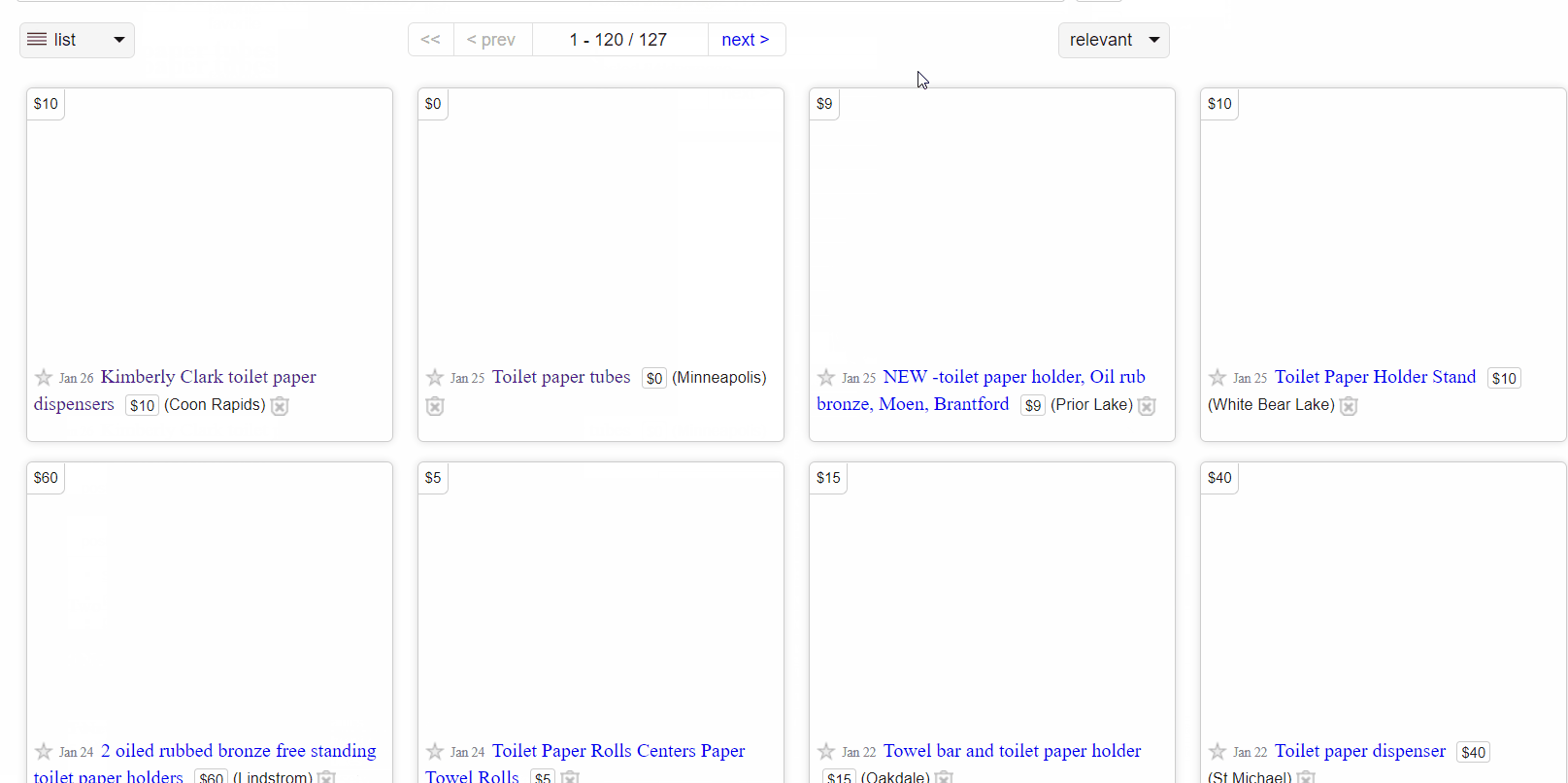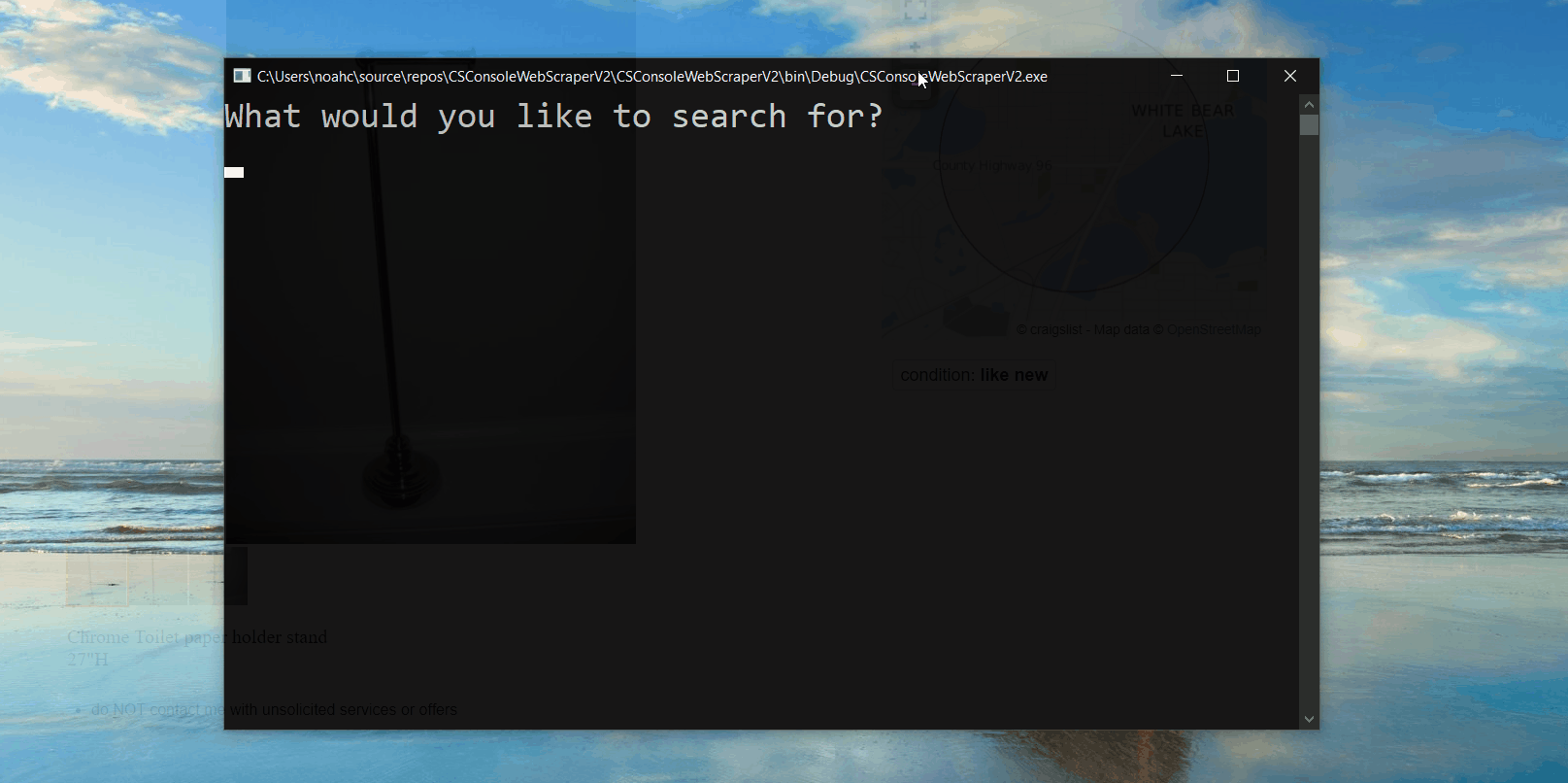
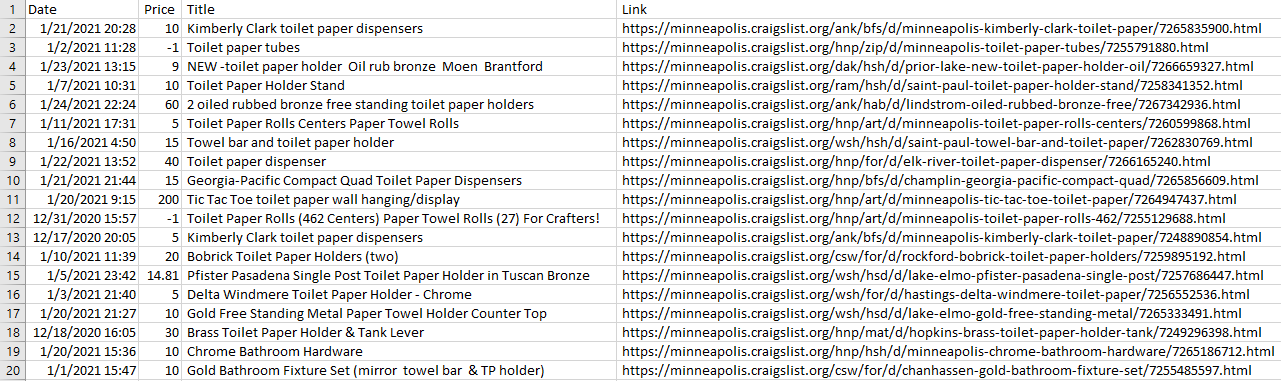
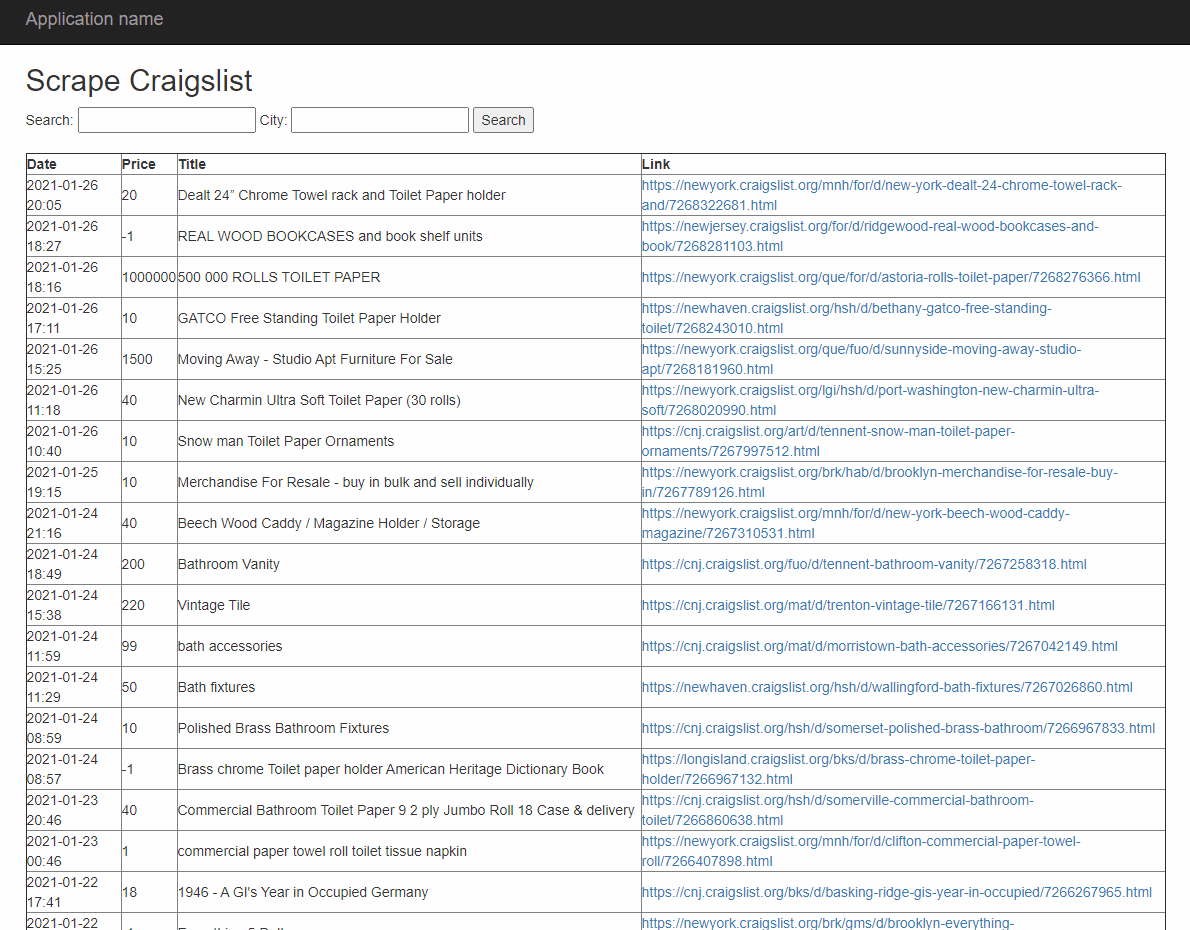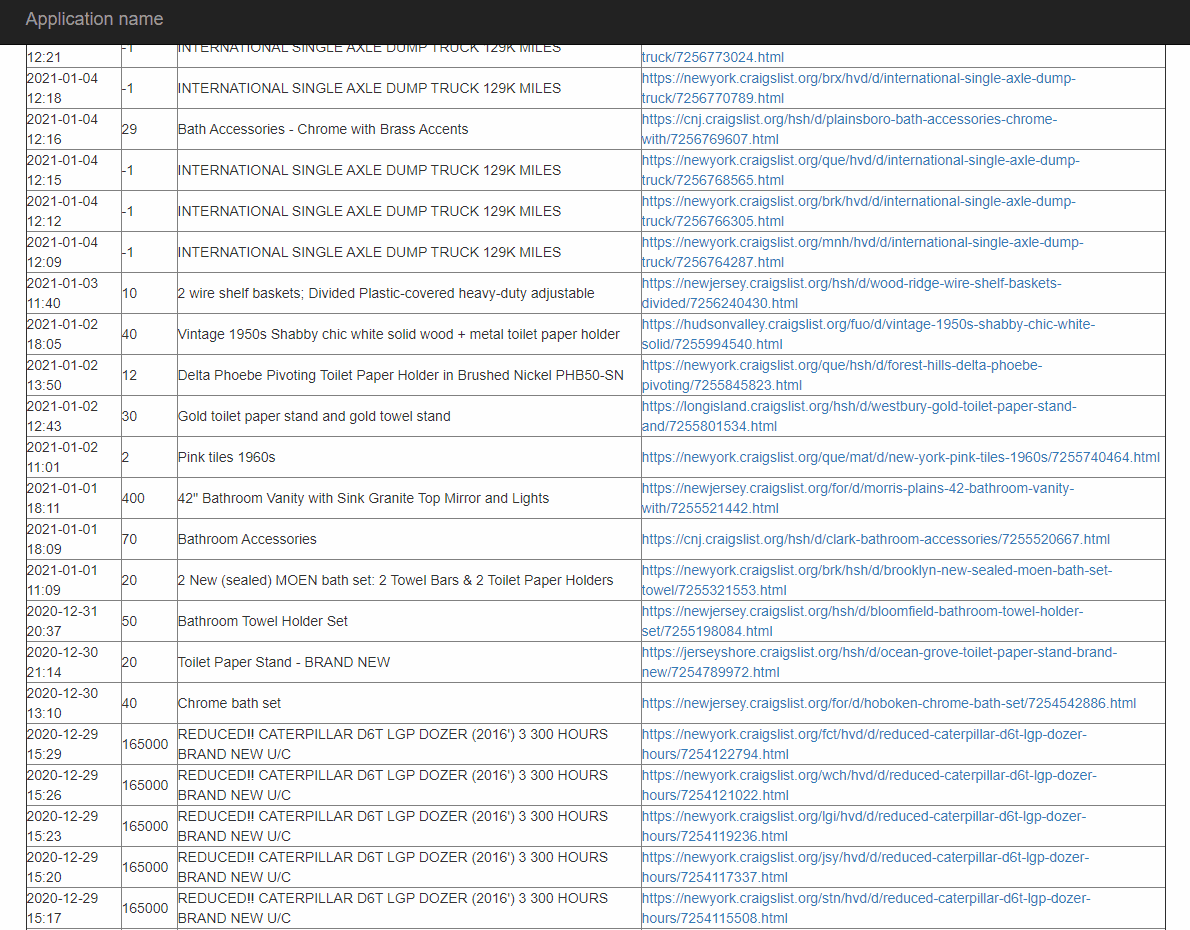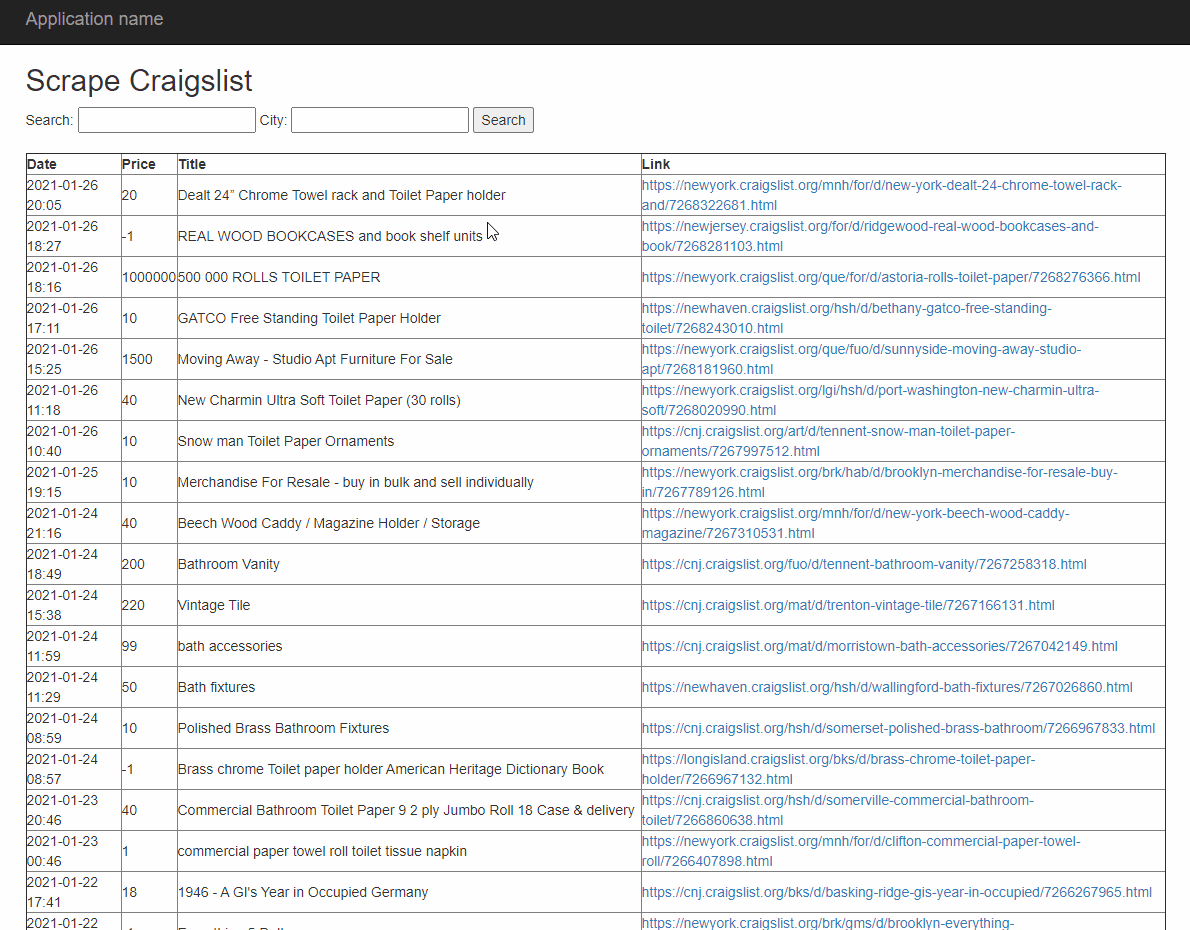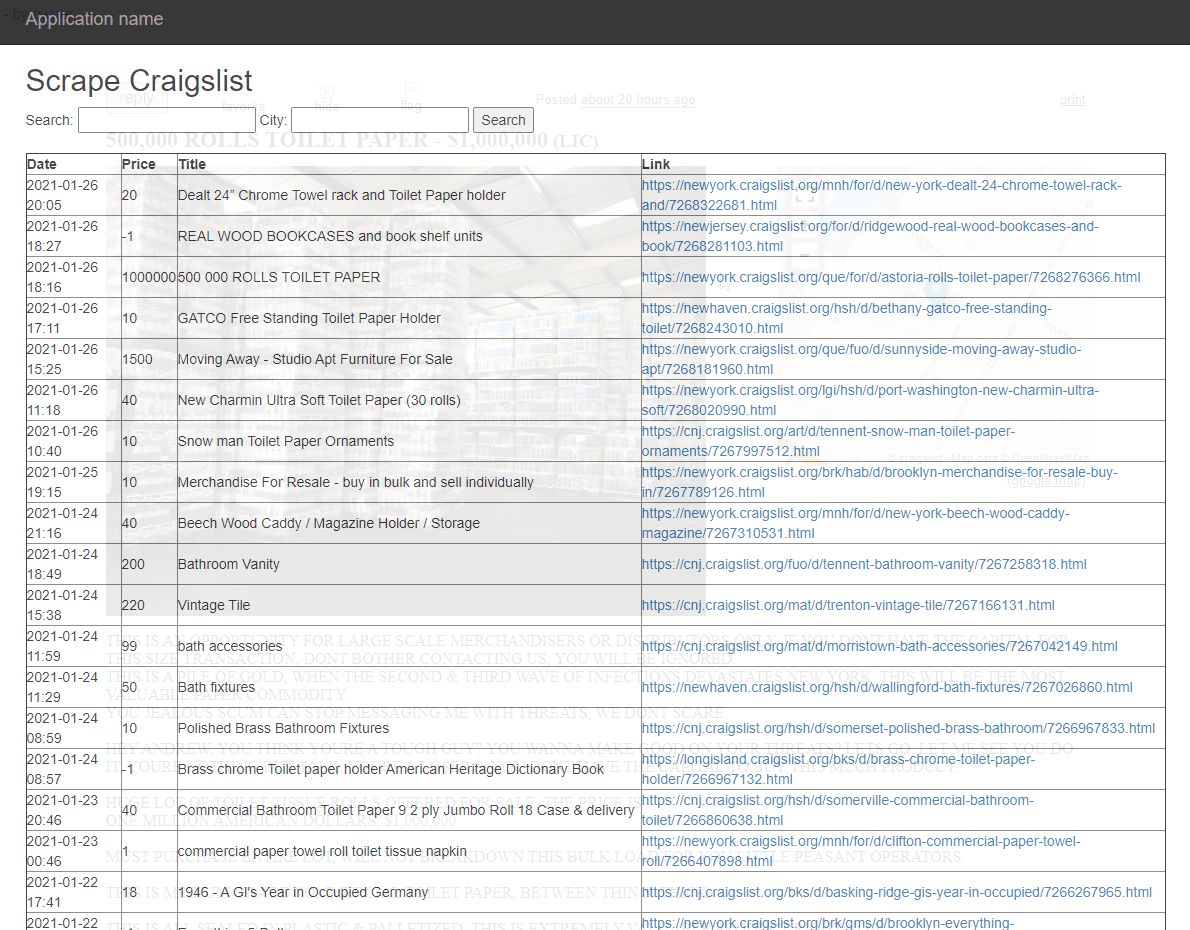
Next, I used my newly gained knowledge to write a console application in C#. I did this because I eventually wanted to make the program into a web application, and I was familiar with the ASP.NET framework. There were slight variations in package names and function calls between the languages, but nothing too drastic. The new program has all the functionality of the program written in Python but adds user interaction in the form of asking users what they are searching for, and in addition to printing the condensed information to the console, it saves the list of posts to a CSV file. This can be seen below.
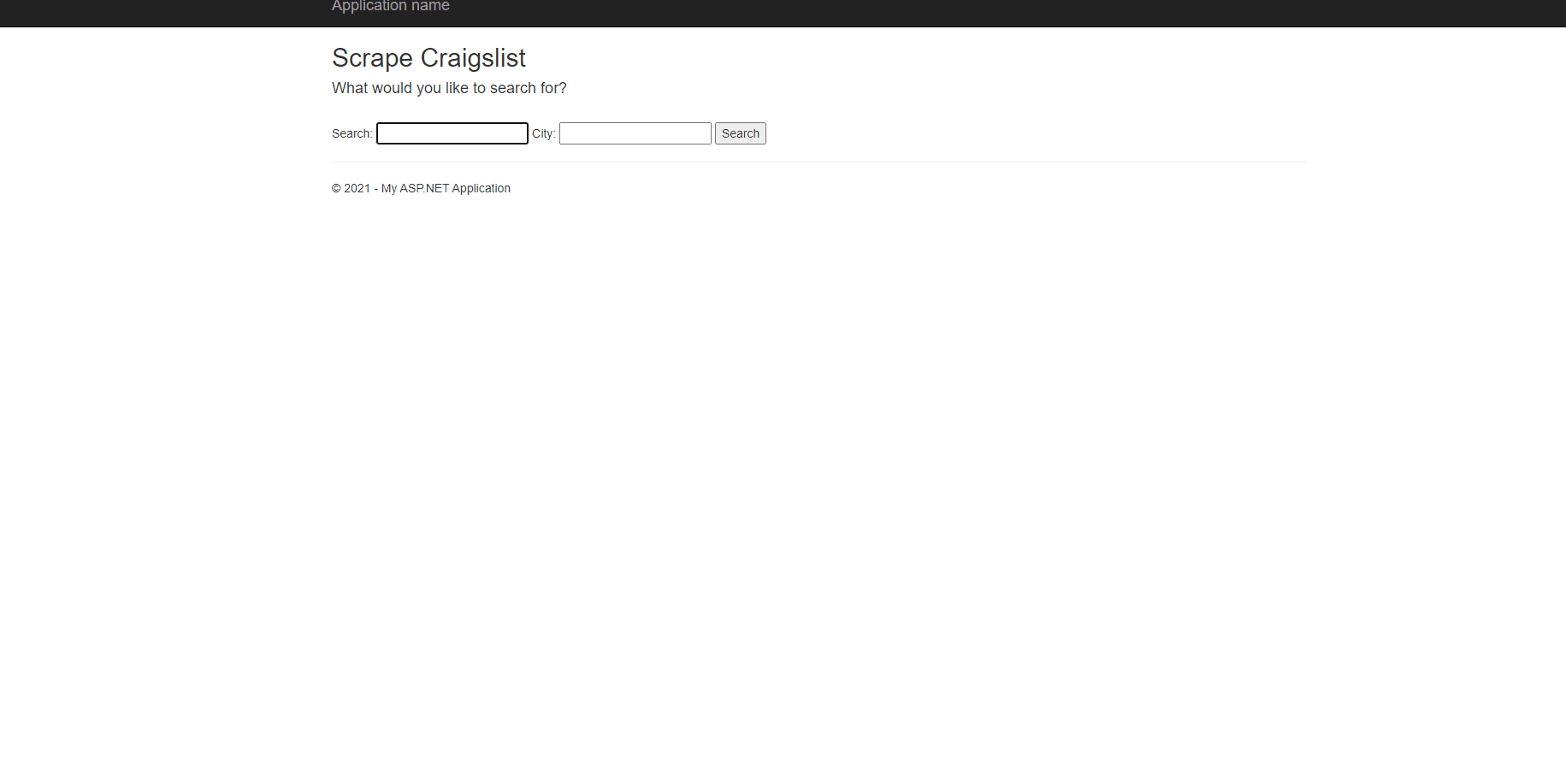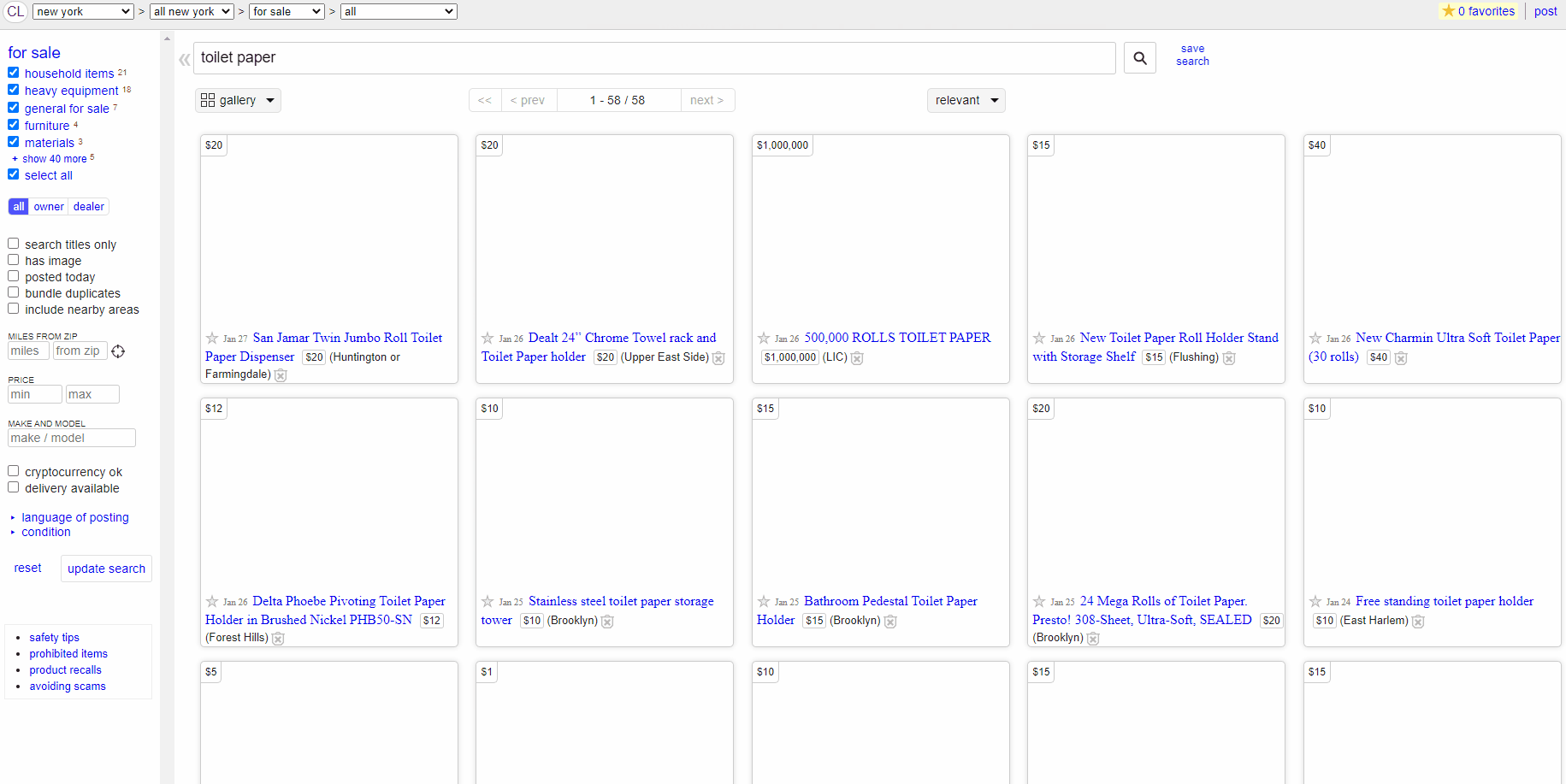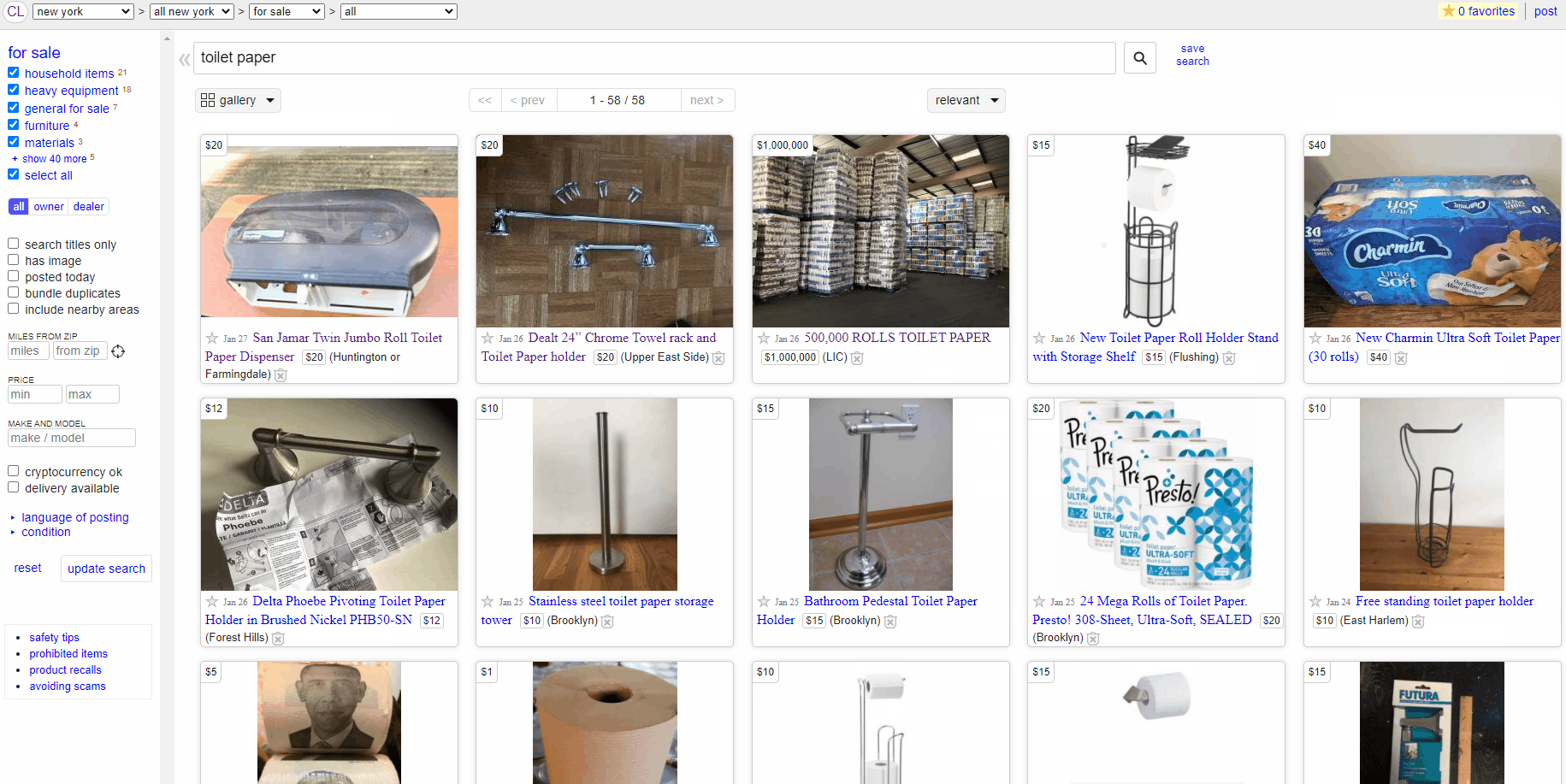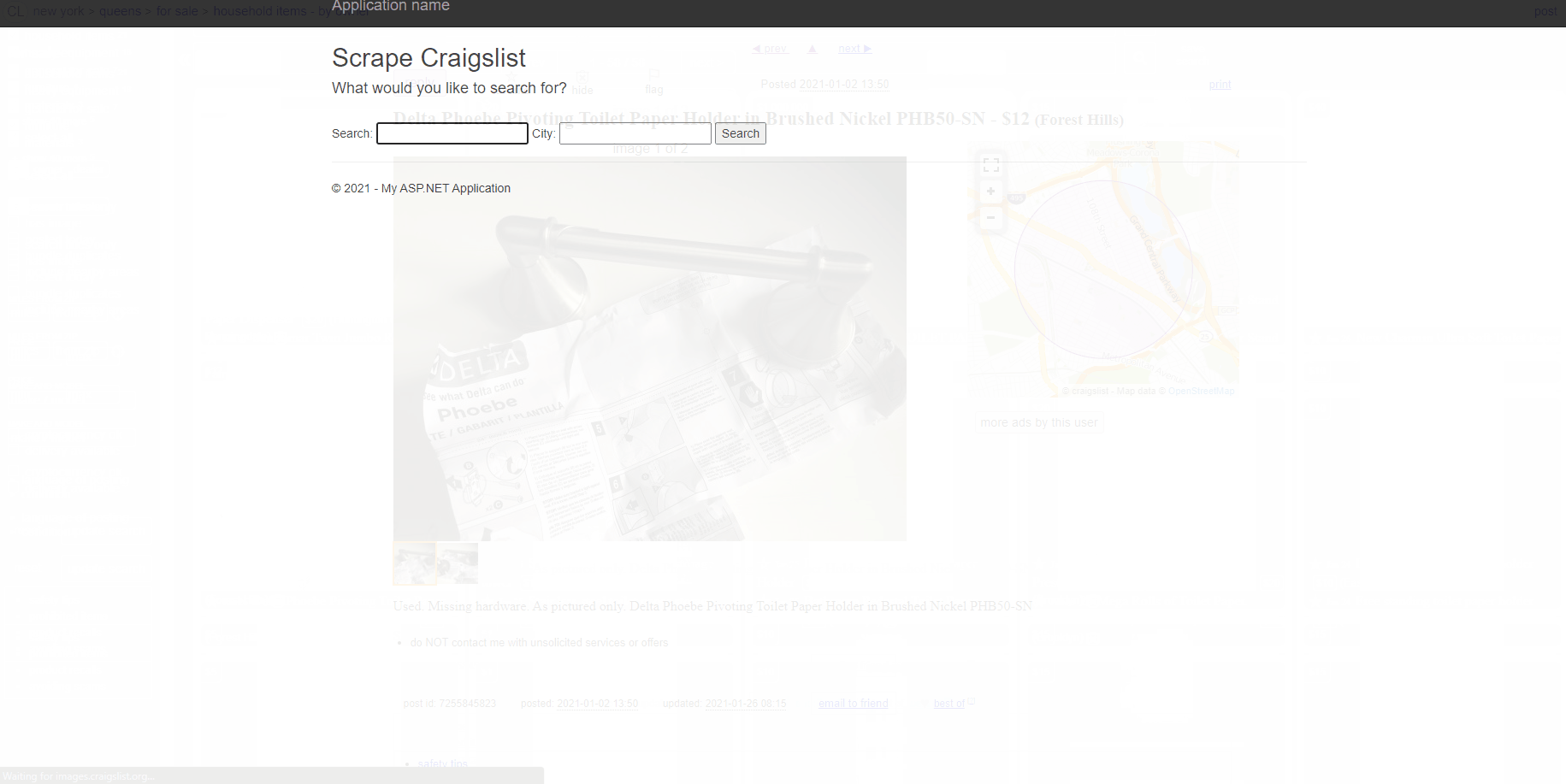
The final features I added gave the user total control. To make the tool more accessible, I built the project into a web application that let users enter their location and what they were searching for. After collecting the necessary information, the program displays it on the webpage. This can be seen below.
Check out my GitHub repository!